
Multiple factors shape the experience of our users. As a mobile developer, but also as an engineering manager, I learned that nothing is more likely to drive users away than a poorly performing app. So this is why we, as developers, should focus on continuously improving this attribute.

This article includes details about (I)why high performance is essential when we build software products, an overview of (II)the most common reasons for performance issues, (III)how to measure performance, and (IV)how Kotlin could help us to build quality products by writing maintainable, secure, and expressive Kotlin code in an idiomatic way. But first let’s define the terms.
🧐 What idiomatic Kotlin means
When we talk about idiomatic Kotlin, we talk about using the features of the language effectively and efficiently.
🧐 What performance means
Performance is a complex term that can include how fast the data is transmitted, stability and scalability, how fast the app responds, or how we use the devices’ resources.
As developers, our role is to develop software for people, and so we should focus on the elements that affect their experience. The best-case scenario is to identify the bottlenecks before they start to become visible and affect the user’s experience.

Now, let’s discover together how performance impacts the user experience.
Based on the studies users appreciate fast-loading pages. A fast website or app gives to users a sense of progress. The users feel they are achieving their goals quickly and that gives them satisfaction.
Also, the studies show that 40% of people abandon a website that takes more than 3 seconds to load. Worst, 79% of users who are dissatisfied with a website’s performance are less likely to buy from the same site again. The bad news is that poor performance will not only negatively affect customer satisfaction. It hurts also the brand of the product. This effect is generated also because 44% of users will tell their friends about a bad experience online.
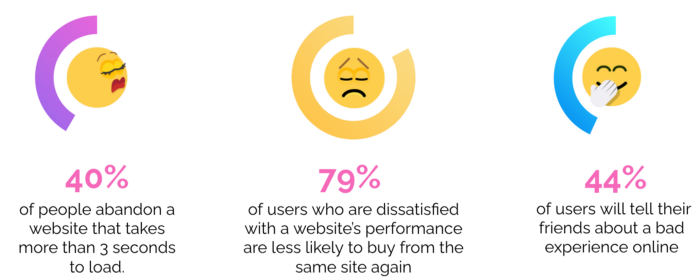
⚠️ So what is the lesson we should learn: poor performance reduces user satisfaction, can drive users away, and damages your brand.

Have you ever been in a queue waiting to buy or pay something? How is the time passing? Fast or slow? Usually slow… The reason for this understanding is the difference between objective and subjective time. Objective time is what a clock measures and subjective time is what we all sense.
When users report that our app or website is slow, we usually focus on making it objectively faster because objective time is easy to measure.
The Difference Threshold or “Just Noticeable Difference” (JND)
Any human observable phenomena needs to have a certain level of difference in order for that difference to be noticeable.
In the book “ Designing and Engineering Time: The Psychology of Time Perception in Software”, the author, Steven Seow recommends we address the next question when the users complain that the app or website is slow: “Do they know that it was slow or did they feel that it was slow?”.
From the same book, research shows that three in four people tend to overestimate waiting times and that such overestimations can be as high as 25% of the actual time. So if your app is slow it should be 25% faster than before to make the difference noticeable.

Now that we have discovered that performance is user experience, let’s address the 4 main reasons for performance issues like memory management, heap fragmentation, resource and memory leaks, or slow rendering when we develop mobile apps.
Kotlin is a JVM language so to carry on we should review the high-level JVM architecture to identify the areas impacted by the performance bottlenecks.
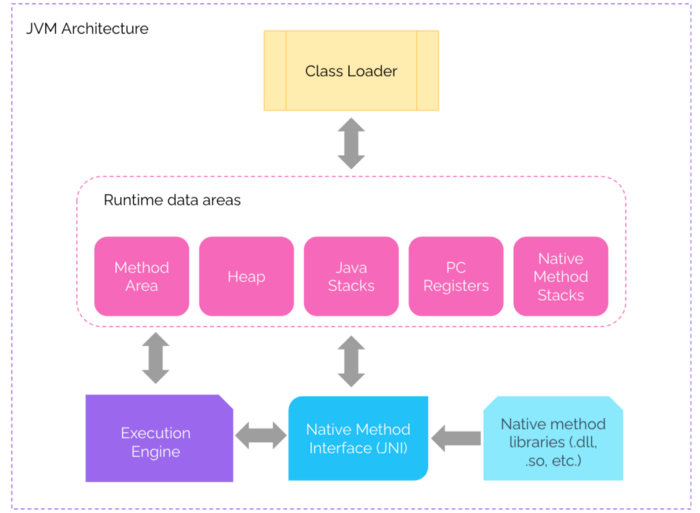
1. Memory management = Garbage Collection
The garbage collector (GC) is responsible to find and destroy the objects that are no more referenced in order to reclaim the memory for reuse. This approach eliminates memory leaks and other memory-related problems. At least in theory.
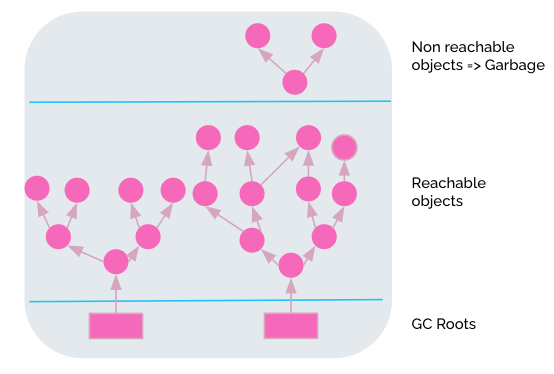
The mechanism is based on a set of root objects that are always reachable. An object is a root if we have local or static variables, active threads, or JNI (Java Native Interface) references.
⚠️ The GC can impact the performance, in a negative way, when the integrity of reference trees is difficult to be achieved. At that moment stop the world or GC pause happens so the execution of all threads is suspended and is connected with compacting phase described below.
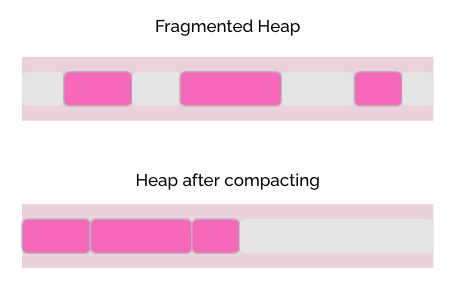
2. Heap fragmentation
The challenge that could occur when we talk about heap fragmentation is that allocating space for new objects begins to take time since it’s starting to be difficult finding the next free block of memory. Also, the space between the allocated blocks of memory could become so big that the JVM will not be able to allocate memory for a new object.
The solution for this challenge is to have a dedicated step that will compact the memory after each GC cycle and so the memory is allocated linearly at one end of the heap.
⚠️ The impact: during the process of compacting the memory the app is suspended.
3. Resource and memory leaks
A resource leak is a situation when a resource that was acquired is not released after it was used. Usually it happens when we work with files.
A memory leak happens when a reference to an object that is no longer used is still stored in another object.
4. Slow rendering
As a mobile developer, you should be aware of how rendering is working because slow rendering is also a performance issue that influences in a negative way the user experience.
The device refresh rate is a hardware characteristic and it is measured in hertz (Hz). It represents how many times per second the image displayed on the screen can be refreshed. Usually, 60 or more frames per second are what users see as high-quality and smooth motion. To achieve this score the application should render one frame at each 16.6 ms. So, when we write the code we should be aware that also the system requires some time to draw a frame, so it will be better to count on only 10 ms.

So far, we have a better understanding of how we define performance and what are the main bottlenecks that impact it. Now, the next step is to learn how to identify these challenges and measure them.
When we must implement new functionality or fix an issue usually we could identify multiple approaches. The important thing to emphasise is that the decision should be done also by being aware of how each option impacts the performance. The decision should rely on numbers and objective information, not on assumptions.
Peter Drucker is often quoted as saying that “you can’t manage what you can’t measure” so also in developing performant apps the measurement give us a helpful insight. The numbers are the objective information and they help us to make informed decisions.
📊 Benchmarking, running the implementation on a real system, is the answer. And also here we could test the performance of certain functions (microbenchmarks), or of some features or flows (mesobenchmarks), or even the entire app (macrobenchmarks).
And because “a goal without a plan is just a wish” (Antoine de Saint-Exupéry) first we should have a testing plan in place that will include: what environment to use, what is the purpose of the testing and the acceptance criteria, what are the tests that should be run, prepare the tests and the data, run the tests and get the results. When we talk about results usually we focus on speed, availability, and scalability.
Tools that could be used to get the results of the performance testing:
🧰 Java Microbenchmark Harness (JMH) — “JMH is a Java harness for building, running, and analysing nano/micro/milli/macro benchmarks written in Java and other languages targeting the JVM.” The challenge with this one is that it’s not capable to handle all cases related to optimising and warming up the JVM
🧰 JVM Debugger Memory View for Android Studio — “This plugin extends the built-in JVM debugger with capabilities to explore objects in the JVM heap during a debug session.”
🧰 Memory View in IntelliJ — “The Memory View shows you the total number of objects in the heap grouped by their class name.”
🧰 JProfiler — “JProfiler’s intuitive UI helps you resolve performance bottlenecks, pin down memory leaks and understand threading issues”
🧰 Flame Graphs — “Flame graphs are a visualisation of hierarchical data, created to visualize stack traces of profiled software so that the most frequent code-paths to be identified quickly and accurately.”
🧰 Dynatrace — “Simplifying cloud complexity and accelerating digital transformation with automatic and intelligent observability.”

There are multiple programming paradigms, and Kotlin checks the functional and object-oriented paradigms. One of the main advantages of using Kotlin is the functional programming approach.

Functional programming is about first-class functions, immutability, pure functions, and Kotlin has a compelling set of features to support this paradigm like:
✅ function types: first, the functions are first-class citizens in Kotlin and it is also allowed to define functions to receive other functions as parameters or to return functions
✅ lambda expressions to pass a block of code in an easy way
✅ data classes to create immutable value objects
✅ a rich set of APIs to work with collections in a functional way
When multiple options are available to make sure you choose the relevant solution you should check and understand what’s happening behind the scenes. To do that, and get the decompiled Java code you could check the following steps.
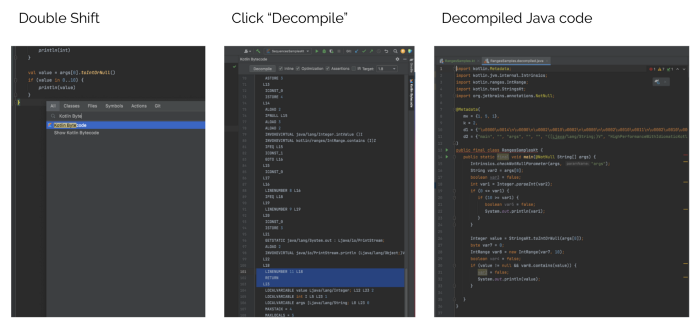
Let’s discover together 10 tips and tricks or hints from the Kotlin world that could make us more aware of the features’ capabilities used in our projects.
💡 Hint 1: Pure functions for parallel processing on multiple CPUs
Pure functions does not have any side effects. A pure function returns the same value for the same parameters. They are a powerful feature for the scenario when you develop apps that use parallel processing on multiple CPUs because the compiler is able to optimise and replace the function invocation with the result.
💡 Hint 2: The high-order functions to reuse the code
The high-order functions allow to reuse the existing behaviour by giving us the possibility to pass a function as a parameter, to return a function or to do both of these things at the same time.
The challenges related to the code from line 10 to line 13 are: the code is difficult to read and if it is often use it could lead to performance issues because each filter function is a loop under the hood.
To solve these challenges we could identity three possible solutions: to define a dedicated predicate (lines 16–18), to implement an anonymous function (lines 21–23) or to use the function composition (lines 26–33).
Function composition is about combining two or more functions in order to reuse the existing functionality. Under the hood, the and() extension function invokes the given three functions one inside another. The infix notation helps us to perform the composition in the code while avoiding nested function calls. The result of the ::titleStartsWithS, ::authorStartsWithB and ::lengthOfTitleGraterThan5 call returns a new function instance which can be easily reused, just like a normal function.
💡 Hint 3: Lambdas to treat functions as values
Lambdas are about passing a block of code directly as a function parameter, which means to treat functions as values. And a closure is a function that has access to variables that are defined in the outer scope. A closure is also known as a capturing lambda because it captures a variable from outside of that function.
In Java is already known that we could capture only final and effectively final variables. The good thing is that by using Kotlin we do not have this restriction, we could capture val and var variables.
Behind the scenes, a lambda is an object that has the Function<out R> type, and Kotlin 1.5.0 is introducing experimental support for compiling Kotlin lambdas into dynamic invocations (invokedynamic), which effectively generates the necessary classes at runtime.
invokedynamic = allows the implementer of the language to define custom linkage behaviour
A lambda can take a varying number of arguments, and to cover as many cases as possible the Functions.kt file was created. This file contains 22 interfaces that extend the Function<out R> interface.
When we want to capture a mutable variable, we have 2 options: either declare an array of one element in which to store the mutable value, or create an instance of a wrapper class that stores the reference that can be changed.
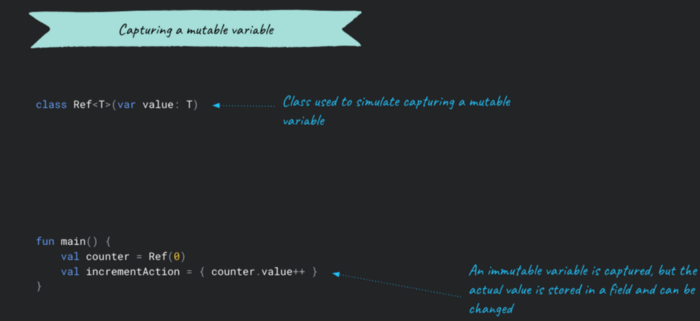
The good news are that in Kotlin, we don’t need to create such wrappers. We can mutate the variable directly. Plus it is possible to pass a varying number of arguments, since the file Functions.kt file contains 22 interfaces that extend the Function<out R> interface. Here we should be careful and respect the clean code principles related to the number of arguments for a function.
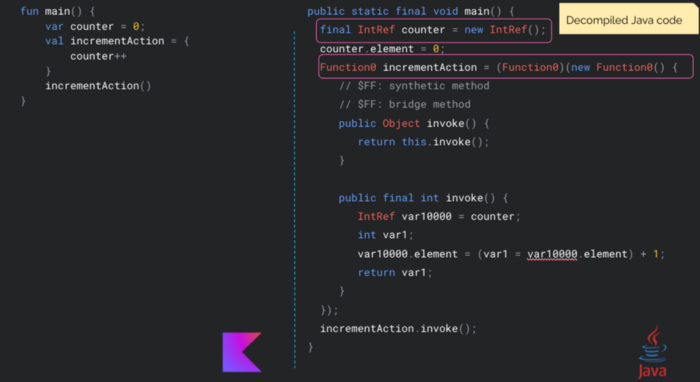
Under the hood, each time when we capture a val, its value is copied, just like in Java. When we capture a var, its value is saved as an instance of a Ref class, just like in the sample from above where the captured value is stored by an instance of the IntRef class. The Ref class contains nested classes that can hold values of all primitive types and objects.
The overhead of using the capturing expressions is that a new Function instance is created every time a lambda is passed as an argument and is garbage-collected after execution. The conclusion is that we should be careful using it. For non-capturing expressions (pure functions), a singleton instance of Function is created.
💡 Hint 4: Inline functions and reified types
Inline functions are responsible to remove the overhead of lambdas. By using the inline modifier on a function, then its body is inserted directly, in the bytecode, in the places where that function is called. By default, the inline modifier is applied to all the lambda parameters.
The advantage is that it reduces the overhead of functions taking lambdas as parameters by avoiding the creation of an instance of Function, which saves memory.
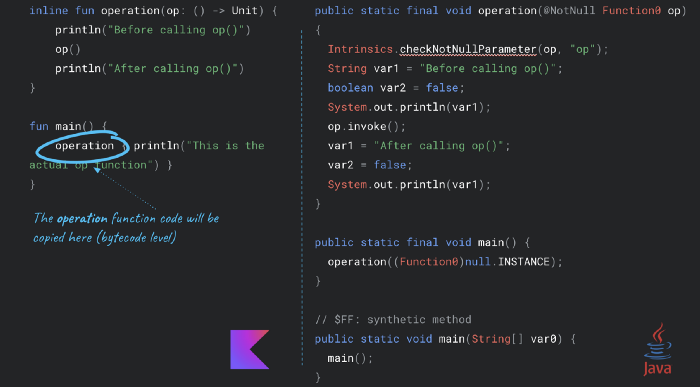
The example from above shows that the compiler does not create an instance of the Function type, so the overhead is removed.
When we have a function with multiple lambdas as parameters we could choose to not inline some of them by using the noinline modifier.
⚠️Warnings:
– If we use the inline modifier on a function that does not have a lambda as a parameter, the rule of thumb is that we will not get any significant performance benefits and also a warning from the IDE. But there are also exceptions where the performance could be improved by inlining the body of a function.
– If we apply the inline modifier on a function that has too many lines of code, and the function is used in multiple places, then this approach will increase the size of our bytecode.
The return keyword behaves differently when it is used inside of a lambda. More precisely it returns from the function where the lambda is located, not just from the lambda itself. This type of return is called a non-local return because it returns from the outside scope. Now, what is the connection with the inline modifier?! To specify that a lambda parameter of an inline function does not support non-local returns, we can mark that lambda with the crossinline modifier.
When to use this approach?! It is helpful when lambda is passed to another execution context.
The reified types are also using the inline modifier and this technique helps us to access the type passed as a parameter at runtime, so the type-erasure mechanism does not happen. Under the hood, by using inline modifier, the then the body of the function is inserted directly, in the bytecode, in the places where that function is called. In our case Reflection comes to help and the compiler knows the exact type used as the type argument in our particular call. Because the generated bytecode references a specific class, not a type parameter, it is not affected by the type-argument erasure that happens at runtime.

💡 Hint 5: Collections & Sequences
When working with collections the general recommendation is to prefer read-only collections because this way we could prevent to have bugs related to the state inconsistency.
Now, when we must choose between using collections or sequences the rule is simple: if we have to process a very big number of elements the sequences are preferred.
On a sequence, we could apply intermediate and terminal operations. The intermediate ones are lazily evaluated, and the terminal ones trigger the postponed (intermediate) operations to be executed.
The conclusion is that eager evaluation runs each operation on the entire collection, and a new collection is created; lazy evaluation processes elements one by one, without copying the elements.

It is encouraged to check the documentation every time we think that we should define a custom operator because it is very possible to be already defined. Also, it is recommended to check the order of the operations because it could impact their performance.
💡 Hint 6: Immutability
Immutability is available by default in Kotlin by using the data classes and we get for free: toString(), hashCode(), equals(), copy(), componentN().
💡 Hint 7: Disposable pattern
Disposable pattern is a pattern used for resource management so it is very helpful to be used when we work with resources (files, streams) to avoid resource leaks. In Kotlin, this thing is achieved by using the extension functions use that release the resources by invoking the close or dispose methods. This function could be applied to objects that implement Closeable.
💡 Hint 8: String templates
When is it necessary to concatenate Strings, we should consider using String templates because under the hood they use the StringBuilder class. Based on the official documentation
“Kotlin 1.5.20 compiles string concatenations into dynamic invocations (invokedynamic) on JVM 9+ targets, thereby keeping up with modern Java versions. More precisely, it uses StringConcatFactory.makeConcatWithConstants() for string concatenation. To switch back to concatenation via StringBuilder.append() used in previous versions, add the compiler option -Xstring-concat=inline.”
💡 Hint 9: @JvmField
We can use the @JvmField annotation to tell the compiler that we want to use these variables as fields, but not as properties. The @JvmField annotation can also be used to prevent the overhead of invoking getters and setters.

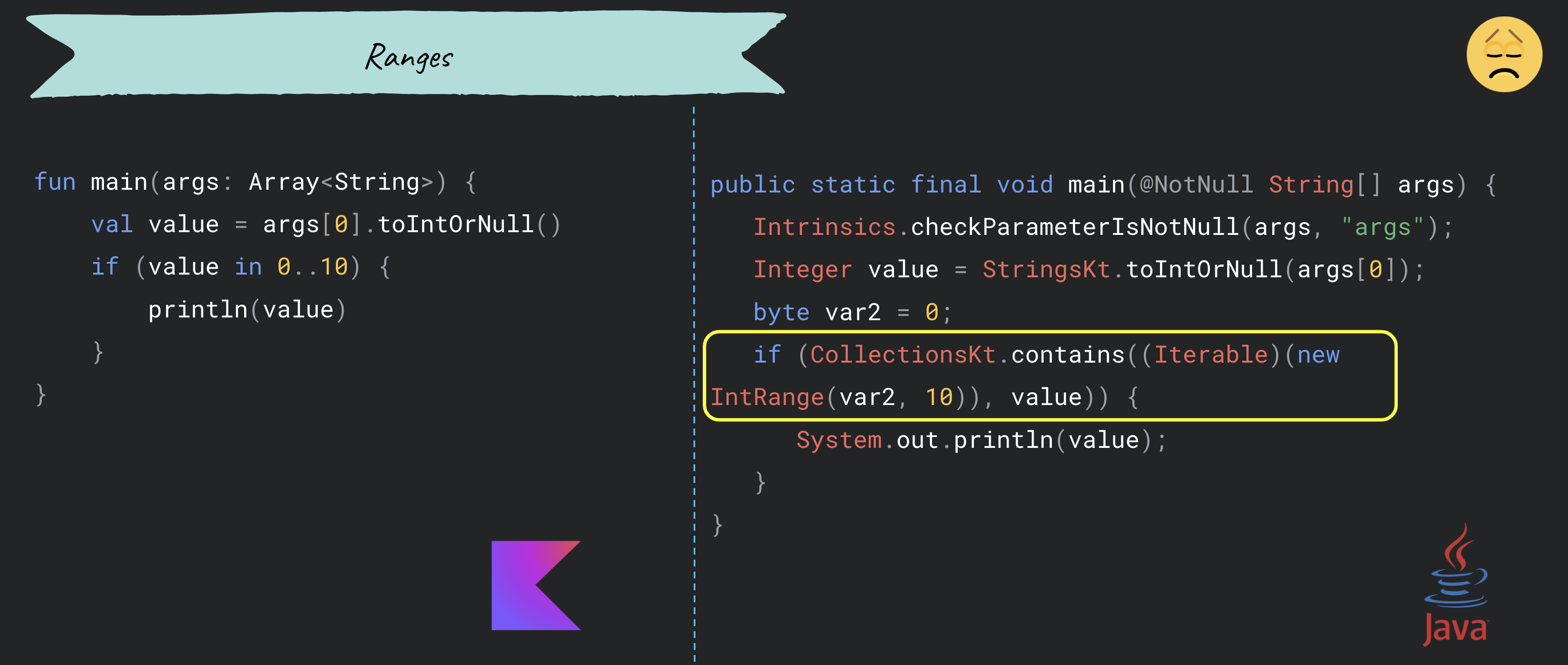
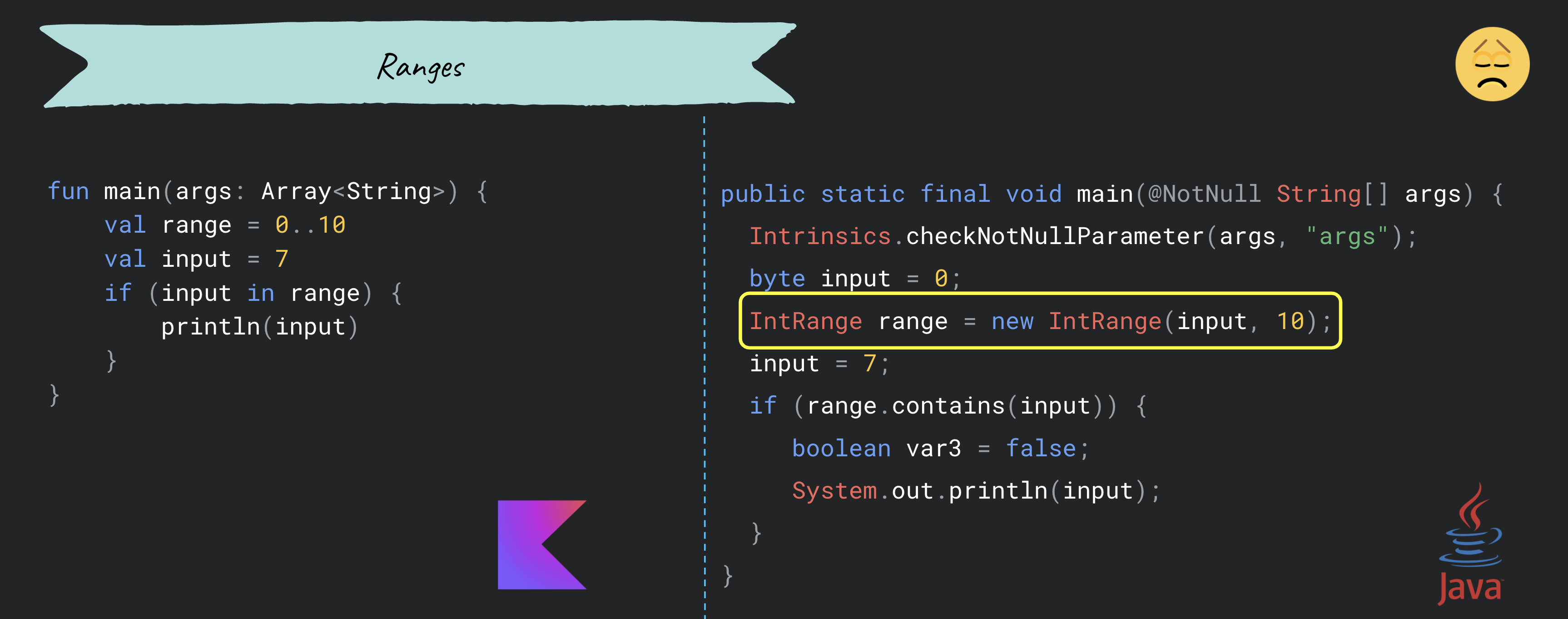
💡 Hint 10: Ranges
When using ranges, based on the chosen approach we could get some runtime overhead or not. To make a summary the recommendation is to not use nullable types with ranges (if it’s possible) because some unnecessary objects will be created, like in the image from the left. The same thing will happen also when we create a reference to a range, like in the image from the middle. The winner approach is the one from the right image.

🎯Conclusion
Based on the topics covered in this article, when we want to implement a new feature or refactor the code the best approach is to evaluate with curiosity all the possibilities. For each option it is helpful to understand what’s happening behind the scenes, and apply objective criteria to make a suitable decision that will help us achieve our purposes.
Enjoy and feel free to leave a comment if something is not clear or if you have questions. And if you have liked the article, please share it. Thank you for reading! 🙏🏽
Happy idiomatic Kotlin! 😉
Check the talk about this topic and the slides (including resources).
